where 子句中的相等操作符
where 子句定义了 SQL 语句的搜索条件,因此它属于索引的核心功能:快速查找数据。一个写得不好得 where 子句是慢查询的第一要素。
接下来的内容将会围绕不同的操作符是如何影响索引的使用,以及如何确保一个索引可以用于尽可能多的查询来展开。
主键
以EMPLOYEES表为例:
1 | CREATE TABLE employees ( |
数据库会自动为主键创建索引。即使没有create index语句,在employee_id字段上也会有一个索引。
以下查询语句通过主键来获取员工姓名:
1 | SELECT first_name, last_name |
SQL Server 中,对应的执行计划如下:
1 | --Nested Loops(Inner Join) |
Index Seek 对应遍历树的操作,它充分利用了索引的对数可扩展性来快速找到条目,几乎与表的大小无关。
RID Lookup 对应读取表数据的操作,因为 Index Seek 只返回一个条目,此阶段也只有一次表访问操作。
所以只有 INDEX UNIQUE SCAN 的情况下不会导致慢查询。
联合索引
联合索引指的是由多个字段组成的索引。需要注意的是,联合索引中字段的顺序对其可用性由很大的影响,所以必须谨慎选择。
假如 EMPLOYEES 表中的 EMPLOYEE_ID 字段不再唯一,需要通过额外的子公司 ID 字段来扩展主键。那么新的主键有两个字段:EMPLAYEE_ID 和 SUBSIDIARY_ID。
对应的索引由以下方式建立:
1 | CREATE UNIQUE INDEX employees_pk |
当查询语句使用联合索引中的所有字段时,数据库能使用 INDEX UNIQUE SCAN。但如果只使用其中一个字段呢?
1 | SELECT first_name, last_name |
执行计划揭露此时数据库没有使用索引,而是执行了全表扫描 (FULL TABLE SCAN)。因此,数据库读取了整张表,并根据 where 子句的条件筛选每一条记录。如果表的数据量增长了 10 倍,全表扫描就需要花 10 倍的时间。这种操作的危险性在于,它在小数据量的开发环境中通常足够快,但在生产环境中会导致严重的性能问题。
在需要检索表的大部分内容时,全表扫描可能是最高效的操作。
数据库不使用索引是因为它不能任意使用联合索引中的一个字段。这是由索引的数据结构所决定的。
数据库根据每一个字段在索引定义中的位置来对索引条目进行排序。第一个字段是主要的排序标准,第二个字段只在两个条目的第一个字段有相同值时才用作排序,以此类推。
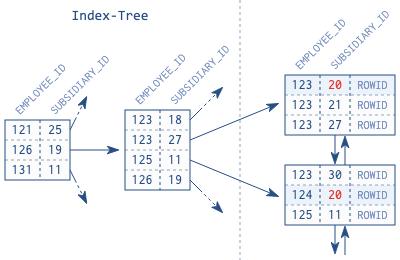
图 2.1 中展示出子公司编号为 20 的条目没有被排在一起,索引树中也没有 SUBSIDIARY_ID = 20 的条目。
在设计联合索引时,最重要的就是考虑如何选择字段的顺序,使以后的查询能更频繁的使用索引来完成。
因为索引中的第一个字段总是可用于搜索,我们可以考虑把子公司 ID 放在索引的第一位。
1 | CREATE UNIQUE INDEX EMPLOYEES_PK |
执行计划如下:
1 | --Nested Loops(Inner Join) |
可以看出,数据库使用了调位置后的索引。 SUBSIDIARY_ID 不是唯一的,所以数据库必须使用 INDEX RANGE SCAN。
一般来说,数据库在使用前导(最左边)的字段进行搜索时,可以使用联合索引。尽管双索引方案也能提供非常好的查询性能,但是单索引方案不仅节省了存储空间,还节省了第二个索引的维护开销。一个表的索引越少,插入、删除和更新的性能就越好。
为了定义一个最佳的索引,你必须了解的不仅仅是索引如何工作,还要知道应用程序如何查询数据。这意味着你必须知道出现在 where 子句中的字段组合。
查询慢的原因
上节中提到的索引可用于所有通过 SUBSIDIARY_ID 字段搜索的查询。如果一个查询有多个可用的索引,查询优化器是如何选择最佳索引的呢?
查询优化器是将 SQL 语句转换为执行计划的数据库组件。这个过程也被称为编译或解析。查询优化器分为两类:
基于成本的优化器 (cost-based optimizer):产生许多不同的执行计划,并为每个计划计算出一个成本值。成本计算基于使用的操作和预估行数。最后,成本值作为挑选最佳执行计划的标准。
基于规则的优化器 (rule-based optimizer):使用硬编码的规则集生成执行计划。这种优化器不太灵活,现在很少使用。
1 | SELECT first_name, last_name, subsidiary_id, phone_number |
以上面的 query 为例,尽管结果集只有一行数据,但是在 subsidiary_id = 30 的数据太多时,反而是全表扫描效率更高。这主要是因为索引查询是逐个读取数据块,在当前数据块被处理之前,数据库不知道下一个要读取的数据库是哪一个。全表扫描必须读取整张表的数据,这样数据库可以一次读取更大的块(多块读取)。尽管数据库读取了更多的数据,但它可能需要执行的读取操作更少。
选择执行计划也取决于表的数据分布,所以查询优化器在估算成本的过程中会使用数据库的 statistics。统计信息包括:
- 字段:不同值的个数,最小、最大值,null 值个数,数据分布
- 表:表的大小(以 rows 和 blocks 来衡量)
- 索引:查找树的深度,叶节点数量,不同键的个数,聚簇因子
优化器使用这些值来估算 where 子句中谓语的分离性 (selectivity)。
如果数据库中缺少 statistics 信息,优化器将使用 default 值,可能会导致生成的执行计划比较低效。
此处最佳的方案当然还是在 LAST_NAME 上建一个索引:
1 | CREATE INDEX emp_name ON employees (last_name) |