Where 子句中的范围搜索
>, < 和 between
INDEX RANGE SCAN 的最大性能风险是叶节点的遍历。
分析以下 query:
1 | SELECT first_name, last_name, date_of_birth |
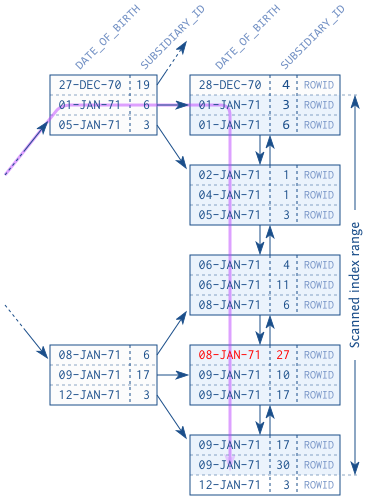
实际的性能差异取决于数据和搜索条件。如果对 DATE_OF_BIRTH 的过滤本身就有很强的选择性,那么这个差异可以忽略不计。日期范围越大,性能差异就越大。
选择性是描述列值数据分布情况的一个重要属性。基数是一列中唯一值的数量。
选择性 = 基数 / 总行数 * 100%
通过这个例子,我们也可以证伪 “选择性最强的列应该在最左边的索引位置 “的说法。如果只考虑第一列的选择性,我们会发现两个条件都匹配 13 条记录。不管我们是只通过 DATE_OF_BIRTH 过滤还是只通过 SUBSIDIARY_ID 过滤,情况都是如此。选择性在这里没有起决定作用,但是一个列的顺序还是比另一个好。
为了优化性能,知道被扫描的索引范围是非常重要的(从执行计划中看)。
like 操作符
like 过滤器在遍历树中只能使用位于第一个通配符 (%) 前的字符。其他的字符只作为过滤器的谓词 (filter predicate),不会缩小需要扫描的索引范围。因此,like 表达式包含两种谓词类型:
- 第一个通配符之前的部分作为访问谓词 (access predicate)
- 其他字符作为过滤谓词 (filter predicate)

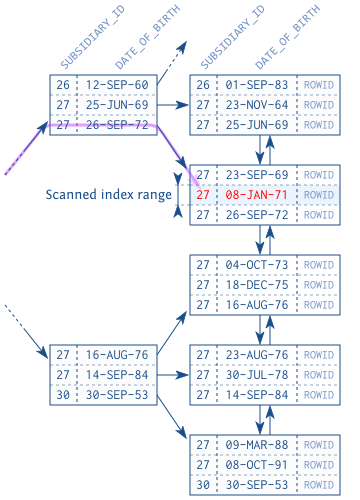
图 2.4 展示了访问谓词的选择性对索引扫描范围的影响。
以通配符开头的表达式需要用全表扫描。
当 like 表达式中的条件通过参数传入时,大多数数据库的优化器会以非通配符开头为前提进行相应优化,但是这不适用于使用 like 进行全文匹配的情景。不使用动态参数是最简单的解决方案,但这增加了优化的开销,也增加了 SQL 注入的风险。
索引合并
优先使用联合索引。在无法避免过滤谓词的时候,把选择性最高的字段排在最左边,以缩小扫描索引的范围。
另一种选择是为每个字段建单独的索引。这时数据库必须扫描两个索引再合并结果。遍历两个索引树再合并中间结果需要大量的内存和 CPU 运行时间。
合并索引有索引关联 (index join) 和位图索引 (bitmap index) 两种方式。
位图索引的最大弱点是 insert, update 和 delete 操作的性能。并发的写操作几乎是不可能的。所以通常用于数据仓库。
许多数据库产品提供了 B-树和位图索引之间的混合解决方案。在没有更好的访问路径的情况下,他们将几个 B-树扫描的结果转换成内存中的位图结构。位图结构不是持久性存储的,而是在语句执行后丢弃的,因此绕过了写扩展性差的问题。缺点是它需要大量的内存和 CPU 时间。这种方法毕竟是优化器的无奈之举。