聚集索引
数据结构
堆表(heap table)数据插入时存储位置是随机的,主要由数据库内部块的空闲情况决定,写入以后不会再移动存储位置,全表扫描时也不一定先插入的数据先查到。
在堆表上建立聚集索引(clustered index)后变成索引表(index-organized table),数据按照索引的排序存储。好处在于:
- 表数据存储在B树的叶节点中,节省了堆结构的空间
- 通过聚集索引查询数据只需要一次index-only scan
但是,当聚集索引无法覆盖,需要在其基础上建另一个索引(secondary index)时,索引表的缺点就会显露出来。索引表中的数据不像堆表中那样静态存储,随着表中数据的更新,数据可以随时移动以维持索引的顺序。因此,二级索引中不能直接存储行的物理位置,必须使用一个逻辑键来代替。
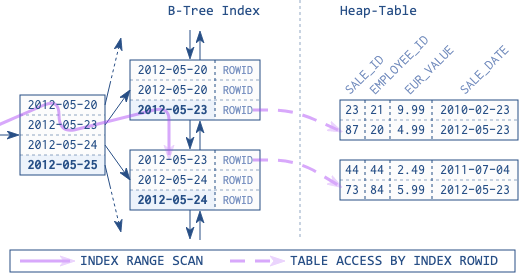
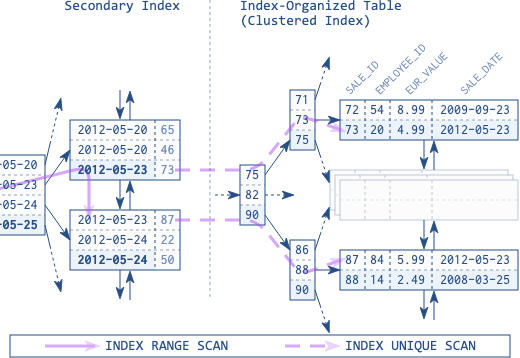
对比图5.2、图5.3可以看出,在索引表中需要遍历两次索引树:
- 在二级索引中查询对应的逻辑键(由聚集索引中的键组成)
- 根据逻辑键遍历聚集索引,找到对应的行
通过二级索引访问索引表的效率很低。
二级索引中存储了每一行的聚集索引的键值。只查询索引中包含的列时,遍历一次二级索引的B树即可;但另一方面,聚集索引的键通常比堆表中的ROWID更长,这样二级索引就会比堆表上的大。
使用场景
索引的数量
如果需要创建二级索引,应该选择非聚集索引。
SELECT操作
如果需要查询的字段都在索引键中,那么非聚集索引效率更高。需要查询表中的其他字段,聚集索引效率更高。
INSERT/UPDATE操作
如果表中的数据频繁更新,应使用非聚集索引。
磁盘空间
非聚集索引需要额外的空间来存储索引树。如果要确保占用磁盘空间尽量小,应使用聚集索引。
索引键选择的最佳实践
- 字段长度要短:长度短可以减少索引树的层级,同时也减少二级索引长度。
- 静态:最好选择极少更新的字段。
- 递增:使用递增字段做索引键可以提高
INSERT效率。 - 唯一性:如果索引键不唯一,SQL Server会新增一个uniqueifier字段(需占用额外的空间)强行使索引键唯一。