数据库索引剖析
索引是什么
An index makes the query fast.
索引是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。它需要占用额外的空间来存储一份表中数据的副本,并且指向对应数据的实际存储位置。
在索引中检索数据就像使用字典的目录。为了保证能快速找到相关条目的位置,索引中的数据必须是排好序的。数据库索引比字典目录复杂的地方在于,数据库中信息会随时发生更新。执行insert, delete和update语句之后,在不操作大量数据的前提下,如果保持索引有序成了一个问题。
数据库系统结合使用了两种数据结构来解决这个问题:双向链表和查找树。
双向链表的使用
数据库使用双向链表来连接索引的叶节点。每个叶节点存储在数据库的最小存储单元:块 (block) 或者页 (page) 中。存放数据的物理块也是同样的大小,通常是几 Kb。数据库在每个块中存储尽可能多的索引条目,也就是说,需要在两个层面维持索引有序:每个叶节点内部的索引条目,以及双向链表中的叶节点。
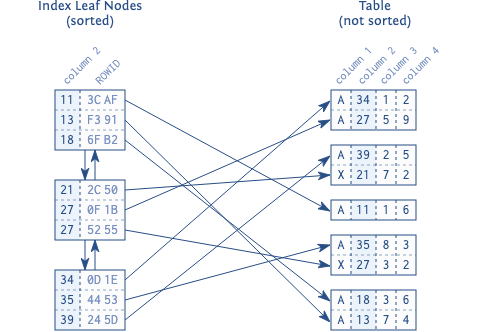
图 1.1 说明表中的数据是无序的。存储在同一个块中不同行的数据之间没有关系,不同块之间也没有关系。
查找树的使用
使用双向链表建立一个有序的逻辑数据结构后,我们还需要第二个数据结构来协助快速地在双向链表中找到对应的条目:平衡查找树 (balanced search tree),简称 B-tree。
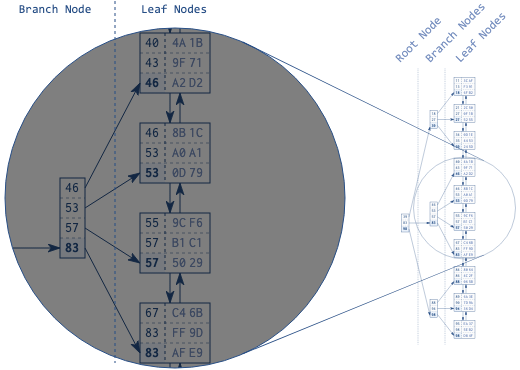
如图 1.2 所示,每个分支节点中的项对应于叶节点中的最大值。每个叶节点到根节点的距离都是一样的。
遍历树是非常高效的操作。因为树是平衡的,访问任意元素需要的步骤数相同,同时因为树的深度是对数增长的,与叶节点的数量相比,树的深度增长非常缓慢。实际运用中,拥有数百万条记录的索引树的深度为 4 或 5。
以图 1.2 中每个节点存储 4 个项,深度为 3 的 B+树为例,总共能存储 64(43) 个项。
索引慢的原因
尽管遍历树很高效,某些场景下索引查询的速度还是不尽如人意。
第一个原因是叶节点链。索引项中的键可能相同,数据库必须读取下一个叶节点以检查是否还有键相同的项。也就说,索引查询不止需要执行树遍历,还需要追踪叶节点链。
第二个原因是访问表中的数据。即使是一个单一的叶节点也可能包含许多被命中的条目,通常是数百个。相应的表数据通常分散在许多物理块中(如图 1.1)。这意味着,每次命中都会有一次额外的表访问。
索引查询需要 3 步:
- 遍历树
- 追踪叶节点链
- 读取表数据
遍历树是唯一一个对访问块的数量有上限的步骤,另外两个步骤可能需要访问很多块,它们会导致索引查询变慢。
Oracle 中一个基本的索引查询通常包含以下 3 个不同的操作:
INDEX UNIQUE SCAN: 只执行遍历树操作。如果存在唯一性约束保证满足筛选条件的只有一行数据,数据库将使用这个操作。
INDEX RANGE SCAN: 执行遍历树和追踪叶节点链的操作。当可能有多行数据满足筛选条件时执行。
TABLE ACCESS BY INDEX ROWID: 从表中检索数据。对于 scan 操作中命中的每一行数据,通常都会触发执行一次对应的表访问。
INDEX RANGE SCAN 可能需要读取索引中的大部分数据。如果每条记录都需要一次表访问,即使使用索引,查询也会变得很慢。